Research
Centre of Competence for Data Science and Simulation
The Centre of Competence for Data Science and Simulation (DSS) is a cross-departmental initiative. Our ambition is to develop infrastructure, tools and competences in in machine learning, big data, microsimulation and geoexperimentation to conduct excellent research and advise policy-makers as well as stakeholders.
The main goal of this Centre is to shape research activities (topics, tools and team) to anticipate the broad diffusion of AI in the economy and society through:
- expand the use and knowledge about AI tools in the LISER community
- include AI tools in project proposals
- develop methods to help increase efficiency (e.g. AI assistance for qualitative interviews)
- make use of Large Language Models (LLM) for economic research including aiding literature research, gaps in research or policy work
- make use of OpenAI for data queries (e.g. team working on online job vacancies)
- networking and building bridges to other local institutions
- being in contact to EU responsible agency for AI
- offer expertise for UPSKILL Project
Events
A key component of rigorous and novel applied and academic oriented research is to rely on a center of excellence to advance the discipline. For LISER, this means developing best practices and fostering a data-driven culture for executing reliable research studies. The DSS has this in its scope while the wide range of seminars offered in this context has been a tangible proof of this. Some of the topics covered over the last months range from:
- machine learning based techniques and natural language processing (presented by Thiago Brant)
- genetics and genomics-related mechanisms, introduced as powerful instruments involving the use of DNA based data in the social sciences (presented by Giorgia Menta)
- good practices for research when using the R statistical software (presented by Etienne Bacher)
- ‘P-Hacking’ discussion, which is one of several concerns regarding research integrity (presented by Felix Stips and Michela Bia).
At LISER, many researchers have been involved in both the preparation and discussion phases of these seminars and gained specific knowledge by engaging with key issues. We are all looking forward to the sequel!
Past seminars
Infrastructure
One of the DSS goals is to develop infrastructure that can be used across-departments to build up skills in machine learning, Big Data methods, micro-simulation, etc., and to develop top standards capacity to work with data both for research and policy work. As a result, DSS is actively developing GitHub.
For LISER, GitHub proves useful as a tool for facilitating collaboration among researchers and optimising workflow. GitHub provides several advantages to researchers and policy makers: it serves as a repository for code, a library for research, and an organization tool for version control. It is also a place that can be used to centralise information (e.g. provide links) to relevant data.
Furthermore, GitHub serves as a Learning Management System (LMS), it encourages both intra-institutional and inter-institutional collaboration, creating a community of shared knowledge and progress. The platform is free and easily accessible with low entry barriers. Our experience is that setting up an account takes just a few clicks. Importantly, putting a project on GitHub does not mean making it available to anyone, unless one decides so.
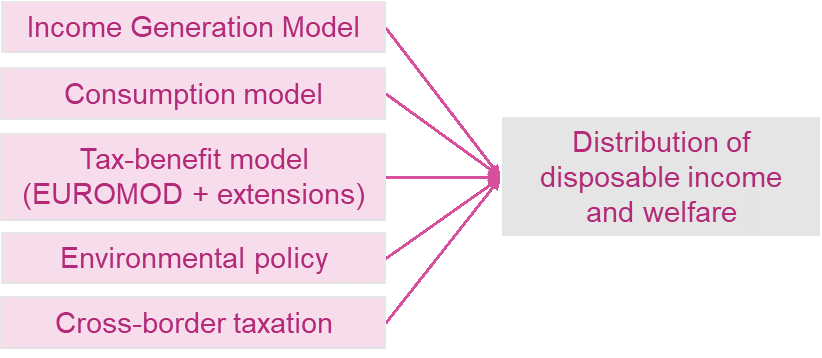
Spatial Data Infrastructure (SDI)
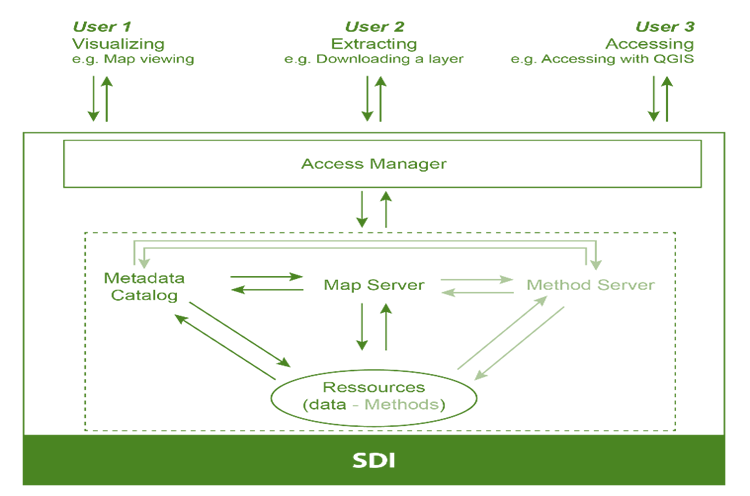
SDI is a strategic project to facilitate efficient geographic research data management and sharing within and outside LISER, with complying with well-established Open Data and Research principles including FAIR (Fair, Accessible, Interoperable, Reusable) and TRUST (Transparency, Responsibility, User focus, Sustainability, Technology). The goal is to facilitate the discovery, access, management, distribution, reuse, and preservation of digital geospatial resources while centralising the management of spatial data and information related to multilateral projects for best sharing and exchange between researchers.
News
Projects
SkiLMeeT
SkiLMeeT studies the determinants of skill mismatches and shortages in European labor markets with a particular focus on the role of the digital and green transition. SkiLMeeT relies, among others, on big data to generate new measures using NLP and ML techniques from online job vacancies, online platforms such as LinkedIn, training curricula and patents.
Patent data on advances in digital and green technologies
This task generates proxies for advances in digital and green technologies using NLP methods and big data. The data used come from the European Patent Office (EPO), the USPTO patent website following Kelly et al. (2021), and Google Patents. We transform the documents into text data, split the text into the relevant sections of the patents, and make sure that all patent texts are machine readable. We next compile a list of keywords describing the patents linked to digital and green technologies and use semantic matching to identify these technologies. For advanced digital technologies, e.g., we use Alekseeva et al. (2021). To match the patent information to the industries that potentially make use of digital and green technologies, we use probabilistic matching procedures.
We differentiate between automation and augmenting innovations and classify breakthrough patents, which serve as an instrumental variable to identify causal effects of new technologies.
Preparing big data from online platforms to analyse the supply and demand of skills in different EU countries
This task makes use of big data from online platforms such as LinkedIn, PayScale, Glassdoor, Indeed and OJV data to analyse the supply and demand of skills (using the keywords of Task 2.1) across European countries.
LinkedIn has over 100 million users in the EU and is therefore considered a particularly reliable data source for the analyses in this project. The platform provides data for both skills supply and skills demand. The skills supply can be derived from the user profiles on LinkedIn and the demand can be extracted from the job vacancies at LinkedIn. Using the job histories, we can also extract information on job transitions in different countries.
Exploiting the time dimension, we can track skills supply, skills demand and job mobility for EU countries and for different sectors over time. We will supplement this information with data from PayScale, Glassdoor, Indeed and OJV to have information on skills and salary at the occupation and company level in EU countries. Various data analysis techniques are used to extract and combine data from diverse sources. We use statistical models and NLP for the data analysis.
AIJOB
The PI, David Marguerit, relies on data science tools in various aspects of his PhD research, enabling him to perform tasks faster and achieve superior results compared to alternative methods.
An illustration of this enhanced efficiency is the project Artificial intelligence, automation and job content: the implication for wages, job mobility and training, where the PI assesses the effect of Artificial Intelligence (AI) exposure at work on wages and employment. For this project, he relies on generative AI to meticulously identify keywords related to AI within a substantial list of 12,000 concepts frequently employed by developers. Research has shown that generative AI performs well in classifying objects. Furthermore, he uses Sentence Similarity to compare different texts between them in terms of meaning. Sentence Similarity, a prominent component of Natural Language Processing, provides a score measuring to what extent two texts have similar meanings. In total, 61,000 pairs of texts are compared.
David’s project with Andrea Albanese on cross-border workers from Belgium to Luxembourg is another example showing how data science techniques can be used. In this project, they assess the effect of becoming cross-border workers on wages after workers return to work in their country of living (i.e. Belgium). First, they use machine learning algorithms, namely Random Forest, to identify the most influential predictors of becoming a cross-border worker. Subsequently, they employ Double Machine Learning to assess the effect of becoming a cross-border worker on wages.
Opportunistic collaboration in a network of robot agents with heterogeneous sensory capabilities
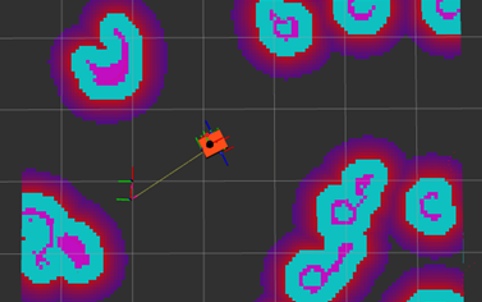
Robot navigation map in the ROS virtual environment
Problem description: This study focuses on the collaborative possibilities offered by the IoT to modern agents (including robots). Agents have no a priori information about the sensory capabilities of other existing nodes. An agent with a specific task could gain time, performance and precision by using the resources and capabilities present in the network. There are many challenges to achieving this opportunistic collaboration. These include a universal ontology for communicating available computational and algorithmic resources and sensory capabilities in a comprehensible language. For example, a security camera can be defined as having a processor, a hard disk, algorithms for detecting people and facial recognition, and producing images of a given resolution, etc. There is also the challenge of representing the world and objects in order to carry out tasks. For example how a robot looking for an object can describe it and how a safe camera with a wide view can help and guide.
We considered a specific case with two agents: a fixed camera at height and a mobile robot that has to carry out a task. The robot has to search for an object that is in the camera's wide field of view and this study seeks to explore and demonstrate the possibilities of IoT as opportunistic collaboration between 2 heterogeneous agents with no prior knowledge of each other's capabilities. This case study was implemented using the ROS (Robot Operating System) environment and produced promising results. The next step is to use real robots (such as Turtlebot, Cherokey, Xgo and Spotdog) to quantify environmental parameters, for example.
Team: Hichem Omrani (PI, research scientist, UDM dept, LISER - Luxembourg), Judy Akl (PhD student, University of Lorraine, France), Fahed Abdallah (Full Prof at the University of Lorraine, France), Amadou Gning (Robotics expert, Createc-UK)
Seed Grants testimonies
Thiago BrantGenerative AI for education
|

The seed grant we secured from the DSS for the integration of a vector database has been instrumental in moving our research forward on the use of Generative AI for education. This financial support enabled us to leverage state-of-the-art AI methodologies, notably within the sphere of Large Language Models. These tools have transformed how we store, retrieve, and dissect extensive data sets, enhancing both efficiency and semantic depth. The incorporation of the vector database has not only optimized our project's responsiveness and accuracy but has also facilitated richer, more nuanced analysis. This innovative approach to data management empowers our team to tackle intricate research challenges, surpassing previous limitations found in the realm of Natural Language Processing.
DSS's mission is to encourage the development of knowledge in data science across diverse fields. In this light, our endeavor at LISER—to craft bespoke AI solutions that bolster research—resonates perfectly with DSS's focus. As our project continues to evolve, this grant will facilitate the expansion of our project, which in turn will allow for the construction of know-how for LISER.
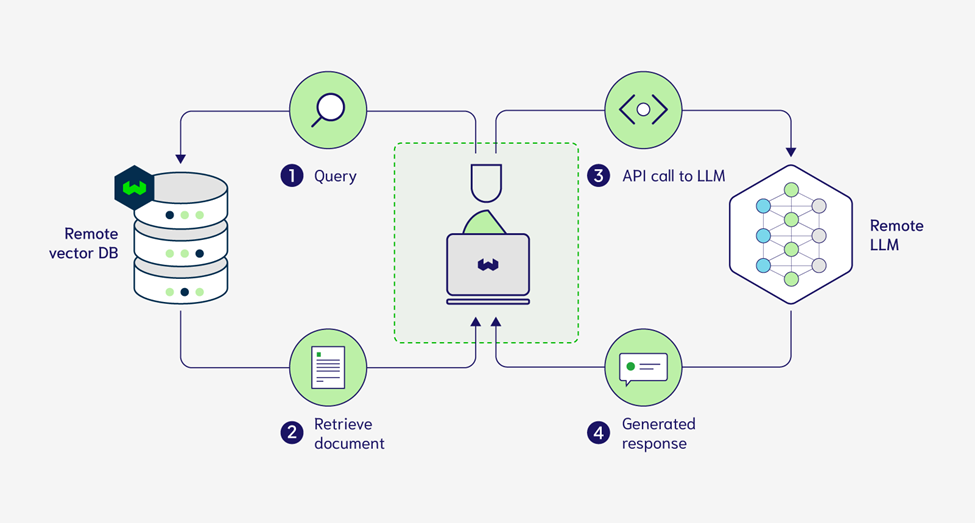
Source: weaviate.io
Terry GregoryAI and Research: Exploiting the Possibilities of OpenAI Models for Empirical Research
|

The project's objective is to leverage OpenAI's large language models, such as GPT, to develop innovative methodologies for analyzing and processing large-scale data in the context of the Centre of Data Science and Systems (DSS) and Luxembourg Institute of Socio-Economic Research (LISER). The project focuses on three key applications:
- Word Processing and Classification in Survey Designs: The first application aims to process open-ended responses in surveys, which produce unstructured data. By using GPT, the project seeks to standardize descriptions of technologies mentioned in survey responses and categorize them efficiently. This can enable better analysis of survey data and provide valuable insights, especially when dealing with large volumes of responses.
- Text Recognition and Extraction of Historical Data: The second application explores the use of GPT for text recognition, including both printed and handwritten content. This involves converting historical documents and records into organized datasets, reducing the need for manual transcription and coding. This approach can be applied to various historical sources, making valuable information more accessible for research purposes.
- Text Analysis and Data Extraction: The third application involves automating data extraction from textual sources, such as online seller profiles or customer reviews. GPT is employed to answer specific questions about the text, facilitating the creation of datasets for various research inquiries. This automated process accelerates data analysis, improves replicability, and offers flexibility in tailoring questions to different texts and languages.
Team: Salvatore Di Salvo (LISER), Julio Garbers (LISER), and Terry Gregory (LISER and ZEW)
Eva SierminskaSpecialization in Economics: JEL codes and beyond
|

Economics, as a discipline, encompasses a broad spectrum of specialization areas, and there is increasing evidence of disparities among underrepresented groups in these fields. Our research addresses questions related to field specialization among early-career economists and its correlation with researchers' gender, country of origin, ethnicity, and other characteristics, as well as its impact on academic outcomes like tenure and promotion. In this emerging but expanding research area, the conventional means of identifying fields have relied on Journal of Economic Literature (JEL) classification codes or self-attribution by researchers. Our work takes advantage of text analysis methods to delve deeper into these complexities.
The DSS grant facilitated the application of text analysis, specifically Latent Dirichlet Allocation (LDA) - an unsupervised machine learning method, for the purpose of topic modeling among dissertation abstracts in Economics. We collected data by scraping approximately 30,000 abstracts from Proquest and merging it with other sources such as EconLit and Academic Analytics. LDA, much like factor analysis for text, uncovers latent 'topics' by recognizing word co-occurrences in documents. It generates a probabilistic word distribution for each topic and a distribution of topics for each abstract, thereby enabling systematic thematic analysis. This approach offers greater stability in the identification of topics and specializations over time, allowing us to identify more accurately primary research fields. The grant provided dedicated time for us to explore the implementation of LDA and the relevant literature, thereby enhancing the robustness of our field specialization identification—a pivotal aspect of our research.
DSS TEAM
Committee
Coordinators
Contact details: ccDSS@liser.lu
Feel free to reach out to us via email for any questions, feedback, inquiries, or suggestions.
